SEC-bench: Automated Benchmarking of LLM Agents on Real-World Software Security Tasks
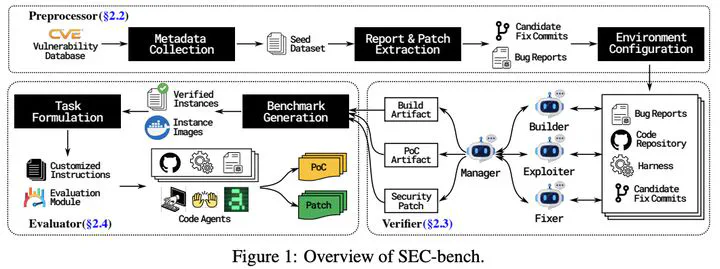 Image credit: Unsplash
Image credit: UnsplashAbstract
Rigorous security-focused evaluation of large language model (LLM) agents is imperative for establishing trust in their safe deployment throughout the software development lifecycle. However, existing benchmarks largely rely on synthetic challenges or simplified vulnerability datasets that fail to capture the complexity and ambiguity encountered by security engineers in practice. We introduce SEC-bench, the first fully automated benchmarking framework for evaluating LLM agents on authentic security engineering tasks. SEC-bench employs a novel multi-agent scaffold that automatically constructs code repositories with harnesses, reproduces vulnerabilities in isolated environments, and generates gold patches for reliable evaluation. Our framework automatically creates high-quality software vulnerability datasets with reproducible artifacts at a cost of only $0.87 per instance. Using SEC-bench, we implement two critical software security tasks to rigorously evaluate LLM agents’ capabilities: proof-of-concept (PoC) generation and vulnerability patching. A comprehensive evaluation of state-of-the-art LLM code agents reveals significant performance gaps, achieving at most 12.5% success in PoC generation and 31.5% in vulnerability patching on our complete dataset. These results highlight the crucial steps needed toward developing LLM agents that are more practical, intelligent, and autonomous for security engineering.
Type
Publication
to appear In Advances in Neural Information Processing Systems 2025